tl;dr -> I collected an implicit feedback dataset along with side-information about the items. This dataset contains around 62,000 users and 28,000 items. All the data lives here inside of this repo. Enjoy!
In a previous post, I wrote about how to use matrix factorization and explicit feedback data in order to build recommendation systems. This is data where a user has given a clear preference for an item such as a star rating for an Amazon product or a numerical rating for a movie like in the MovieLens data. A natural next step is to discuss recommendation systems for implicit feedback which is data where a user has shown a preference for an item like “number of minutes listened” for a song on Spotify or “number of times clicked” for a product on a website.
Implicit feedback-based techniques likely consitute the majority of modern recommender systems. When I set out to write a post on these techniques, I found it difficult to find suitable data. This makes sense - most companies are loathe to share users’ click or usage data (and for good reasons). A cursory google search revealed a couple datasets that people use, but I kept finding issues with these datasets. For example, the million song database was shown to have some issues with data quality, while many other people just repurposed the MovieLens or Netflix data as though it was implicit (which it is not).
This started to feel like one of those “fuck it, I’ll do it myself” things. And so I did.
All code for collecting this data is located on my github. The actual collected data lives in this repo, as well.
Sketchfab
Back when I was a graduate student, I thought for some time that maybe I would work in the hardware space (or at a museum, or the government, or a gazillion other things). I wanted to have public, digital proof of my (shitty) CAD skills, and I stumbled upon Sketchfab, a website which allows you to share 3D renderings that anybody else with a browser can rotate, zoom, or watch animate. It’s kind of like YouTube for 3D (and now VR!).
Users can “like” 3D models which is an excellent implicit signal. It turns out you can actually see which user liked which model. This presumably allows one to reconstruct the classic recommendation system “ratings matrix” of users as rows and 3D models as columns with likes as the elements in the sparse matrix.
Okay, I can see the likes on the website, but how do I actually get the data?
Crawling with Selenium
When I was at Insight Data Science, I built an ugly script to scrape a tutoring website. This was relatively easy. The site was largely static, so I used BeautifulSoup to simply parse through the HTML.
Sketchfab is a more modern site with extensive javascript. One must wait for the javascript to render the HTML before parsing through it. A method of automating this is to use Selenium. This software essentially lets you write code to drive an actual web browser.
To get up and running with Selenium, you must first download a driver to run your browser. I went here to get a Chrome driver. The Python Selenium package can then be installed using anaconda on the conda-forge channel:
conda install --channel https://conda.anaconda.org/conda-forge selenium
Opening a browser window with Selenium is quite simple:
from selenium import webdriver
chromedriver = '/path/to/chromedriver'
BROWSER = webdriver.Chrome(chromedriver)
Now we must decide where to point the browser.
Sketchfab has over 1 Million 3D models and more than 600,000 users. However, not every user has liked a model, and not every model has been liked by a user. I decided to limit my search to models that had been liked by at least 5 users. To start my crawling, I went to the “all” page for popular models (sorted by number of likes, descending) and started crawling from the top.
BROWSER.get('https://sketchfab.com/models?sort_by=-likeCount&page=1')
Upon opening the main models page, you can open the chrome developer tools (ctrl-shift-i in linux) to reveal the HTML structure of the page. This looks like the following (click to view full-size):
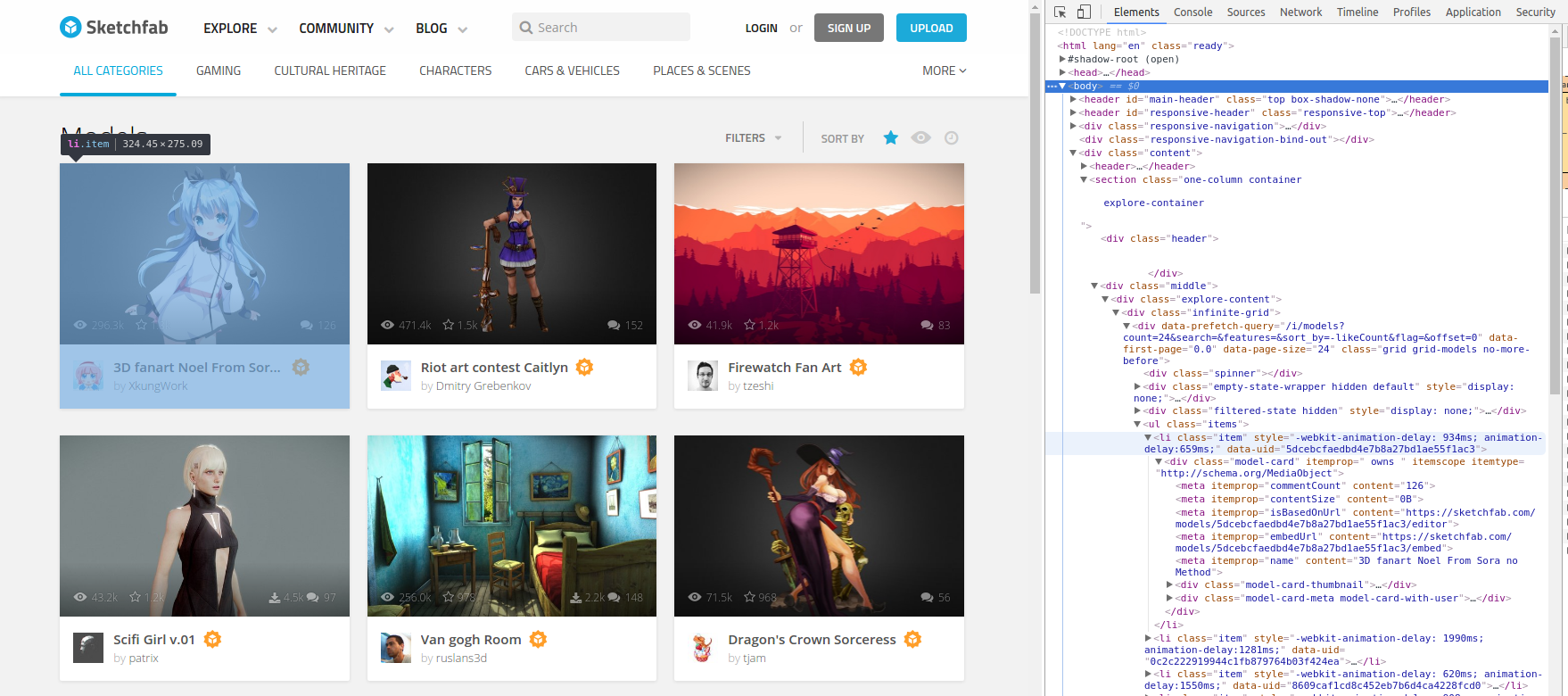
Looking through the HTML reveals that all of the displayed 3D models are housed in a <div> of class infinite-grid. Each 3D model is inside of a <li> element with class item. One can grab the list of all these list elements as follows:
elem = BROWSER.find_element_by_xpath("//div[@class='infinite-grid']")
item_list = elem.find_elements_by_xpath(".//li[@class='item']")
It turns out that each Sketchfab model has a unique ID associated with it which we shall call its model ID, or mid. This mid can be found in each list element through the data-uid attribute.
item = item_list[0]
mid = item.get_attribute('data-uid')
The url for the model is then simply https://sketchfab.com/models/mid where you replace mid with the actual unique ID.
I have written a script which automates this collection of each mid. This script is called crawl.py in the main repo. To log all model urls, one runs
python crawl.py config.yml --type urls
All told, I ended up with 28,825 models (from October 2016). The model name and associated mid are in the file model_urls.psv here.
Apple of my API
In order to log which user liked which model, I originally wrote a Selenium script to go to every model’s url and scroll through the users that had liked the model. This took for-fucking-ever. I realized that maybe Sketchfab serves up this information via an API. I did a quick Google search and stumbled upon Greg Reda’s blog post which described how to use semi-secret APIs for collecting data. Sure enough, this worked perfectly for my task!
With a mid in hand, one can hit the api by passing the following parameters
import requests
mid = '522e811044bc4e09bf84431e6c1cc109'
count = 24
params = {'model':mid, 'count':count, 'offset':0}
url = 'https://sketchfab.com/i/likes'
response = requests.get(url, params=params).json()
Inside of response['results'] is a list of information about each user that liked the model. crawl.py has a function to read in the model urls file output by crawl.py and then collect every user that liked that model.
python crawl.py config.yml --type likes
After running this script collecting likes on 28,825 models in early October 2016, I ended up with data on 62,583 users and 632,840 model-user-like combinations! This data is thankfully small enough to still fit in a github repo (52 Mb) and lives here
Even though these likes are public, I felt a little bad about making this data so easy to publicly parse. I wrote a small script called anonymize.py which hashes the user ID’s for the model likes. Running this script is simple (just make sure to provide your own secret key):
python anonymize.py unanonymized_likes.csv anonymized_likes.csv "SECRET KEY"
The likes data in the main repo has been anonymized.
Information on the side
An exciting area of recommendation research is the combination of user and item side information with implicit or explicit feedback. In later posts, I will address this space, but, for now, let’s just try to grab some side information. Sketchfab users are able to categorize models that they upload (e.g. “Characters”, “Places & scenes”, etc…) as well as tag their models with relevant labels (e.g. “bird”, “maya”, “blender”, “sculpture”, etc…). Presumably, this extra information about models could be useful in making more accurate recommendations.
crawl.py has another function for grabbing the associated categories and tags of a model. I could not find an API way to do this, and the Selenium crawl is extremely slow. Thankfully, I’ve already got the data for you :) The model “features” file is called model_feats.psv and is in the /data directory of the main repo.
python crawl.py config.yml --type features
What’s next?
With all of our data in hand, subsequent blog posts will dive into the wild west of implicit feedback recommendation systems. I’ll show you how to train these models, use these models, and then build a simple Flask app, called Rec-a-Sketch, for serving 3D Sketchfab recommendations.