Two years ago, I tried to build a SaaS product for monitoring machine learning models. Luckily for you, that product went nowhere, so I figured I ought to share some code rather than let it continue to fester in a private GitHub repo.
The monitoring service was designed to ingest data related to model predictions and model outcomes (aka “gold labels” aka “ground truth” aka “what actually happened”). The service would then join and clean this data and eventually spit back out a bunch of metrics associated with the model’s predictive performance. Under the hood, the service was just an unmagical ETL system. Glorified data laundering, if you will.
Central to my operation was an event collector. Naively, I thought that many machine learning teams were operating in the world of real-time predictions, so I built an API for them to POST their predictions to on the fly when the model ran. In reality, most teams were operating in the world of batch predictions and still are (pro tip: talk to people before you build things).
While maybe not yet useful for ML monitoring, I’m going to spend this post describing how the event collector works. I feel like it’s easy to read blog posts on companies’ tech blogs with fancy diagrams of their giant system, but, when you go to build a system yourself, there’s a giant chasm between vague diagrams and actual code. So, I’ve built, deployed, and open sourced an event collector just for this blog post.
The event collector is powering the “dashboard” below showing how many people have visited this page and how many have clicked on the Click Me button. The full code is provided in my serverless-event-collector repo should you want to replicate this yourself.
Page Views: ...
Button Clicks:
Why Serverless?
Because I’m cheap and don’t value my time.
In hindsight, going serverless was a terrible idea. During development, I did not want any fixed costs (I had no funding or income), and horizontal scalability was attractive. I figured I could always port my serverless code over to dedicated servers if the economies of scale made sense. The piece that I did not factor into my calculation was the fact that it would take me so much longer to write serverless code. The biggest slowdown is the iteration loop. Lots of magical things happen under the serverless hood, so it can be hard to debug your code locally. But, it can take a while for your code to deploy, hence the slow iteration loop.
Seeing as I eventually shut down my project and got a real job, I could have saved significantly more money if I had built faster, quit sooner, and started cashing paychecks a couple months earlier.
Despite my negativity, it’s still really fucking cool that you can do things with code where scale is an afterthought and cost can automatically spin down to zero. The latter is what allows me to not think twice about deploying my toy event collector for the sake of this silly blog post.
Requirements Before Implementation
Before I reveal the dirty secrets of my data operation, let’s first talk through the requirements for said system:
- I need a way for the event collector to receive events (aka data) from the user.
- I need to authenticate the user. Randos shouldn’t be able to send data to another user’s account.
- I may need fast access to information about the events, such as the total number of events.
- I need to store the events somewhere such that they can be queried later.
Given the above requirements, let’s talk implementation.
Show Me the Diagram
One of the best lessons I was taught about writing project and design docs at work was to draw a damn diagram. So please, enjoy the event collector diagram below.
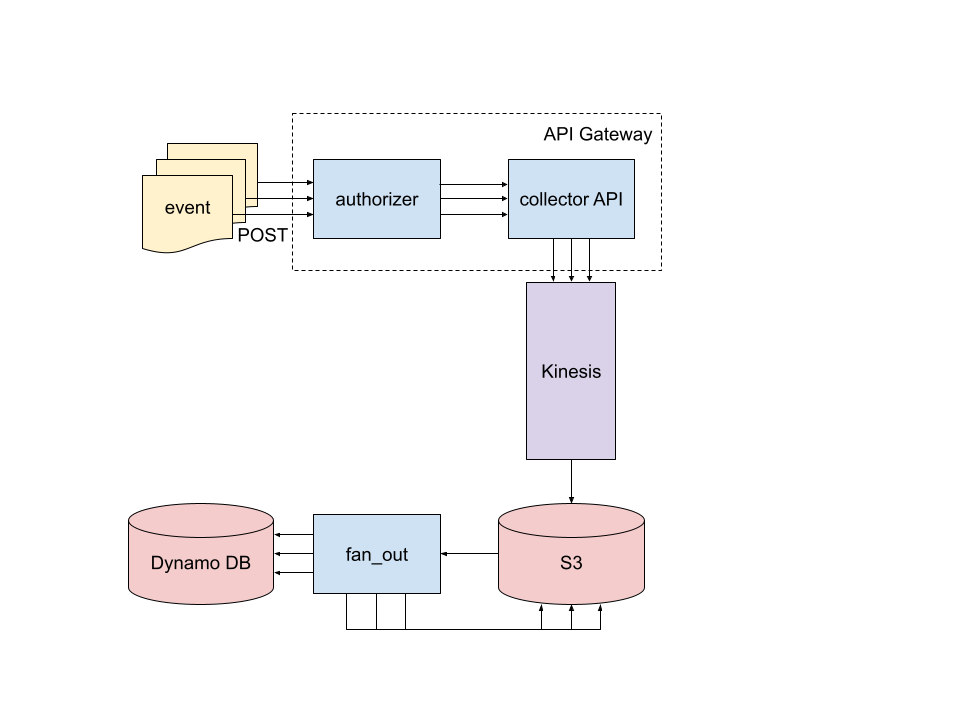
What’s going on here? We’ll start at the upper left and perform a whirlwind tour. Along the way, I’ll mark off each of the resolved aforementioned requirements.
Events are POSTed as JSON-serialized data to a public facing API (this resolves requirement 1️⃣). The API lives in API Gateway and consists of two Lambda functions: the authorizer checks the Basic Authentication info in the request and allows or denies the request (2️⃣). Allowed requests get forwarded to the collector Lambda function which is actually a FastAPI server deployed as a Lambda function. collector validates the request and then drops it into Kinesis Firehose which is a Kafakaesque managed service. collector also updates DynamoDB tables which maintain a count of each event type for each user. These tables are used to power endpoints for GETting real time event counts and are how the dashboard for this blog post gets populated (3️⃣).
Batches of events from Kinesis get dropped into a bucket on S3. Objects created in that bucket trigger the fan_out Lambda function in which events from the main Kinesis bucket get copied into user-specific buckets partitioned by event-type and time (4️⃣).
The entire serverless event collector is deployed together using the serverless framework with full configuration defined in serverless.yml.
Respect My Authority
When the user sends an event to the event collector, they must first get past the authorizer. The user provides their username and password via Basic Authentication. The requests library supports this with the auth argument:
import requests
url = ...
payload = {...}
username = ...
password = ...
response = requests.post(
url, json=payload, auth=(username, password)
)
The authorizer is an API Gateway Lambda authorizer (formerly known as a custom authorizer), and it checks if the username and password are valid. In production, I would recommend storing the user’s password in something like AWS Secrets Manager. The authorizer can then lookup the user’s password and confirm that the provided password is correct. AWS Secrets Manager has a fixed cost per month for each stored secret. While the cost is small, I wanted to minimize the cost of this blog post, so I just hardcoded a username and password into my authorizer.
The authorizer returns a specifically formatted response which tells API Gateway whether or not the user has access to the requested API endpoint. Below shows an example response allowing the user access to all POST requests to the collector API.
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "execute-api:Invoke",
"Effect": "Allow",
// account_id:api_id/stage
"Resource": "arn:aws:execute-api:us-east-1:0000000000:XXXYYY/prod/POST/*"
}
]
}
There are a couple other useful tricks you can employ with a Lambda authorizer. You can cache the authorizer response for a given input. This way, you do not have to waste time or money calling the authorizer function (and potentially AWS Secrets Manager) for every API call. To cache the response, set the authorizerResultTtlInSeconds parameter for the authorizer to the number of seconds to cache the response for. Then, return a usageIdentifierKey field in the authorizer response. The value should correspond to the input that you want to cache. For example, you could return the username and password as the usageIdentifierKey so that any future requests using the same username and password will hit the cache instead of calling the authorizer.
The other trick you can employ is that you can return a context field in the response which will be forwarded on to the actual API that the user is calling (the collector, in our case). In my authorizer, I add the username to the context so that the collector API has access to the username without the user having to explicitly provide it in their event data.
Moving to Collections
Authorized events make it to the collector API which validates the event data, drops the event into a Kinesis queue, and updates relevant DynamoDB tables for real-time statistics. By using the FastAPI framework for the collector API, we get data validation and API docs for free. Let’s take a look at how this all works with some simplified code showing the endpoint for tracking button clicks.
import time
from fastapi import APIRouter, Request
from pydantic import BaseModel
from collector.context_utils import get_username
from collector.dynamo import ButtonClickCounter, update_count
from collector.kinesis import put_record
router = APIRouter(prefix="/button")
class ButtonClick(BaseModel):
session_id: str
button_id: str
@router.post("/click", tags=["button"])
def button_click(button_click: ButtonClick, request: Request):
record = button_click.dict()
record["username"] = get_username(request)
record["event_type"] = "button_click"
record["received_at"] = int(time.time() * 1_000) # Milliseconds since Unix epoch
put_record(record)
update_count(ButtonClickCounter, record["username"], record["button_id"])
return {"message": "Received"}
After some library imports, a router is instantiated. This is a FastAPI object that is like a Flask blueprint, if you’re familiar with those. The main idea is that every endpoint defined with the router object will live under the /button prefix. The endpoint shown will be at /button/click. Routers allow you to logically group your endpoints and code.
After the router, the ButtonClick pydantic model is defined. FastAPI is well-integrated with pydantic, which is a great library for type hint-based data validation. By setting the type hint for the button_click argument in the button_click() function to the ButtonClick pydantic model, we ensure that JSON POSTed to the button/click endpoint will be converted into a ButtonClick object, and the conversion will be validated against the expected keys and types. Jesus, who named everything “button click”?
The button_click() function houses the code that runs when the /button/click endpoint is POSTed to. Some extra information like a timestamp gets added to the event record, the record is put into a Kinesis queue, the DynamoDB ButtonClickCounter table is updated, and finally a response is returned to the user.
Fan Out
Why do events get dropped into a Kinesis queue? I don’t know. I originally did it because it seemed like the future looking, scalable thing to do. In actuality, it ended up just being a convenient way to transition from operating on individual events to batches of events. Kinesis will batch up records based on time or storage size (whichever limit gets hit first) and then drop a batch of events into S3.
The creation of this file containing the batch of events triggers the fan_out Lambda function. This function is not particularly interesting. It “fans the records out” from the main Kinesis S3 bucket into individual buckets for each user. The records then get partitioned by event_type and time and land at a path like
button_click/year=2021/month=6/day=1/hour=13/some_record_XYZ
I partitioned by time in that manner because then you can run a Glue crawler over the bucket, and your generated table will automatically have time partitions as column names. Once the table has been generated, you can then query the data in Athena.
SOServerless
So I’ve mentioned a couple Lambda functions making up this serverless event collector: authorizer, collector, and fan_out. The event collector can be considered serverless because it basically just relies on these Lambda functions. I’d consider the event collector to be even more serverless-y because I provision the Kinesis queue and DynamoDB tables so that I only pay when I read or write to them. The only real fixed cost is the S3 storage cost, and this is pretty minimal unless this blog post really blows up.
If you’re going to make a system out of Lambda functions, then you really shouldn’t manually zip up and deploy your Lambda functions. Life’s too short for this, and while it may not be too bad the first time, it’s going to be a pain when you inevitably need to update things or roll back your changes. If you have a lot of AWS things to create, then you should probably use Terraform or CloudFormation. If you only have a couple things, then ask your local DevOps expert if the annoyingly named serverless framework is right for you.
As far as I can tell, serverless is a command line node library that converts declarative YAML into declarative CloudFormation (shall we call this a transpiler?). It’s relatively straightforward for simple things, and confusing for me for complicated things. I think it’d be less confusing I could debug by reading the generated CloudFormation, but then I’d probably just use CloudFormation, so yeah.
I was planning to explain a bunch of stuff about my serverless YAML file, but I’m kind of sick of staring at it, so I’ll just say “Go check out the serverless.yml file in the repo if you’re interested”.
I should mention that serverless is not just for Lambda functions. My entire event collector gets deployed with serverless. That includes hooking all of the collector endpoints up to API Gateway and placing the authorizer in front, creating the Kinesis queue, creating the bucket for Kinesis events, and attaching the fan_out function to the Kinesis bucket. It took a while to get this all working, but it’s nice that I can now create the entire system with a simple serverless deploy command.
One tricky bit was deploying a FastAPI server as a Lambda function on API Gateway. serverless actually has pretty good support for hooking up Lambda functions to API Gateway. If you want to deploy a Flask app to API Gateway, then there’s a serverless-wsgi plugin for that. The wrinkle for FastAPI is that it’s an ASGI server.
Thankfully, the Mangum library makes this relatively painless. All you have to do is wrap your FastAPI app with a Mangum class like so:
from mangum import Mangum
from my_fastapi_service import app
handler = Mangum(app)
and then you reference the handler object as your handler for the Lambda function that you’re deploying with serverless.
Oh hey remember how I said doing things serverless was a pain? I somehow forgot to complain sufficiently about this.
There were a zillion issues with doing things serverless.
I’m not even sure if all the issues were due to the serverlessness of my system because sometimes it’s hard to know! I had all sorts of CORS issues, issues with the FastAPI root_path, python packaging issues for Lambda functions, issues between CORS and the Lambda authorizer, IAM issues, and did I mention CORS? Maybe the problem isn’t so much the serverlessness as it is using many different AWS products together as opposed to a good ol’ EC2 instance.
One day, we will program on the cloud like we program on operating systems. Until then, have fun staring at ARNs.